


EdgeLake empowers businesses to unlock the true potential of their edge data. By turning the edge into a virtual data lake, companies extract real-time insights from their distributed edge data without centralizing the data.
What is EdgeLake?
EdgeLake, an LF Edge project, creates a decentralized network specifically designed for the edge.
An EdgeLake Network seamlessly captures, stores, and manages data at its source, while providing a complete and unified view of the data to satisfy SQL queries from edge and cloud applications, as if the data is organized in a centralized database.
Using EdgeLake, companies manage their data on each distributed edge node using pre-configured services and gain real-time insight from their distributed edge data without dependency on the cloud. See how the ecosystem uses EdgeLake.
NEW: ⚡ EdgeLake Meets AI: Your Data Lake Just Got Conversational
Talk to your edge infrastructure like you’d talk to a colleague. EdgeLake’s new MCP integration lets you use Claude or other LLMs to unlock real-time insights instantly.
Game-changing examples:
🎯 “Why did production slow down at Factory B last Tuesday?” Correlate sensor data, identify bottlenecks, get answers in seconds
🌡️ “Compare HVAC efficiency across all warehouses—where are we wasting energy?” Instant multi-site analysis
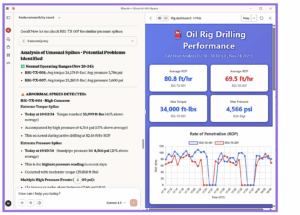
🚨 “Show me all pressure anomalies from offshore rigs in the Gulf” Real-time monitoring meets natural language
📈 “Forecast equipment failures based on vibration trends” Predictive maintenance through conversation
Stop querying. Start asking. Your edge data is now exposed through an LLM-ready interface — the same pattern used by ChatGPT, Claude, and custom models.
The EdgeLake Advantage
EdgeLake is a single and unified stack that replaces engineering efforts by deploying a stack of configurable services on each edge node. An EdgeLake deployment and services offer:
- Plug-and-Play Virtual Data Lake: Effortlessly transform your edge into a virtual data lake with our simple-to-deploy solution.
- Distributed Data Management: A specialized protocol that manages and hosts data at the distributed edge.
- Unified Data Access: A virtual layer that services the distributed data as a single and unified collection of data, without the need to physically centralize the data.
- Single System Image (SSI): A protocol that provides a SSI to distributed resources (servers, switches, gateways, devices).
- Scalable Data Platform: A data platform that scales horizontally to address the growth of the data at the edge.
When EdgeLake is deployed, it offers APIs into 3 layers:
Layer 1: Services Layer
This layer offers data management services including local (and pluggable) databases that host data locally and is integrated with other services, (such as services for data ingestion, schema creation, a rule engine, and a globally shared metadata).
EdgeLake’s services are enabled by native commands, making deployment simple; by selecting services from an integrated and unified stack, a user configures the profile of each node, rather than developing proprietary solutions or integrating functionalities from diverse products.
Layer 2: Data Virtualization Layer
The Data virtualization layer represents the distributed data as a single and unified collection of data. Applications connect to the virtual layer and interact with the distributed edge data as if it is organized in a single relational database.
Using a REST API, applications select a virtual table from a list of logical databases. Then, select the columns for the selected table to issue a SQL query which is satisfied without the need to know which are the edge nodes that host the relevant data. This process keeps data in place and services edge data to the applications that need the data without centralizing the data. The query protocol operates like MapReduce – when a query is issued, the nodes at the edge that host the relevant data are identified and the query is routed to the selected edge nodes. These nodes process the query concurrently and the results sets from all the participating nodes are aggregated and returned as a unified result to the application.
Operating at the edge using MapReduce enables efficient processing of large-scale datasets in a distributed environment, providing scalability, simplicity, and parallel processing capabilities. The EdgeLake Query APIs utilize REST and SQL, offering flexibility and seamless integration with a broader ecosystem of tools and libraries.

The diagram above compares the current approach where data needs to be first organized in the cloud and serviced from centralized databases, to EdgeLake, where data remains in-place and serviced from the Edge.
Layer 3 – Coordination Layer
The coordination layer maintains meta-information, system configurations, enforces network wide rules (i.e. unified schemas), and makes information available to all the member nodes. Examples of metadata included in the Coordination Layer are node memberships (i.e., what nodes are part of the network), and data maps (i.e., where data is stored, the list of tables and their schema).
The Coordination Layer is extended to host users’ and applications’ data and EdgeLake provides APIs to update and query from the Coordination Layer. Users can select between 2 implementations of the Coordination Layer – The first is a blockchain based implementation and the second is by assigning the Coordination Role to one of the nodes in the network.
For the applications, the Coordination Layer is transparent – they only issue data queries or status requests (to the network) which are satisfied as if the edge is a single machine, and the data is hosted on a local database.
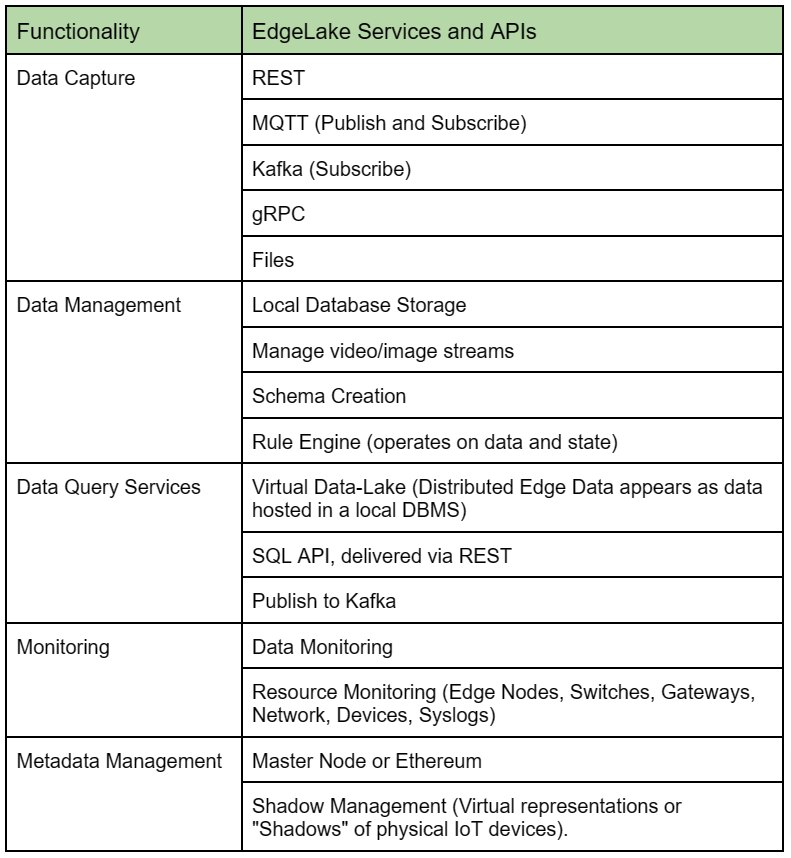
Functionalities and APIs
Origin and History of EdgeLake
EdgeLake is the open-source version of AnyLog, a virtual data layer developed by AnyLog Inc. that spans across distributed edge environments. Designed to unify and simplify edge data access without relying on the cloud, EdgeLake enables real-time, decentralized data management. In May 2024, EdgeLake was accepted as a Stage 1 project within the LF Edge umbrella of the Linux Foundation, marking its formal entry into the open-source ecosystem. In November 2025, EdgeLake graduated to a Stage 2 project.
Get Started With EdgeLake

Info Pager - EdgeLake Integration with Open Horizon
Download Now
Plug-and-Play Smart Edge Solutions: Tourisme Participations' Success with EdgeLake
Download Now