
Pushing AI to the Edge (Part One): Key Considerations for AI at the Edge
Q&A with Jason Shepherd, LF Edge Governing Board member and VP of Ecosystem at ZEDEDA

This content originally ran on the ZEDEDA Medium Blog – visit their website for more content like this.
This two-part blog provides more insights into what’s becoming a hot topic in the AI market — the edge. To discuss more on this budding space, we sat down with our Vice President of ecosystem development, Jason Shepherd, to get his thoughts on the potential for AI at the edge, key considerations for broad adoption, examples of edge AI in practice and some trends for the future.
So Jason, how do you define edge AI and what are the reasons to embrace the practice?
AI at the edge means that we’re simply moving at least portions of the process out of centralized data centers closer to where the data originates and where decisions are made in the physical world. This trend is being driven by the exponential growth of devices and data and reasons include reducing latency and network bandwidth consumption and ensuring autonomy, security and privacy. Today the edge component of AI typically involves deploying inferencing models local to the data source but even that will evolve over time.
What are the key considerations in deploying AI at the edge compared to in the cloud?
First off, it’s important to consider that many of the general considerations for deploying AI in the cloud carry over to the edge. For instance, results must be validated in the real world — just because a particular model works in a pilot environment doesn’t guarantee that the success will be replicated when it’s deployed in practice at scale when external factors of camera angle and lighting come into play. Just Google “AI chihuahua muffin” for an example of the real-world challenges in detecting similar objects!
Another growing challenge is dealing with the proliferation of deep fakes that can throw off business results, drive false sentiments on social media, or worse. Further, developing ethical AI and data trust will also be key in ensuring that the AI is being deployed in a responsible and impactful way, regardless of whether it’s at the edge or in the cloud.
When it comes to the edge, first it’s important to understand the key considerations spanning the edge to cloud continuum. Over the past few months, we’ve worked closely with the Linux Foundation’s LF Edge community to create a comprehensive taxonomy for edge computing based on inherent technical and logistical trade offs. This taxonomy is outlined in detail in a technical white paper that will be released next week that also provides an overview of the LF Edge organization and its current projects — all seeking to build an open, harmonized foundation for edge computing and IoT.
We think this paper will go a long way towards clearing up the current market confusion around the “edge” because most existing taxonomies are biased to one market lens — e.g., telco, IT, Operations Technology (OT), consumer — and have ambiguous breakdowns between categories. Meanwhile, the LF Edge taxonomy breaks the continuum down into top level tiers and subcategories based on hard tradeoffs, for example, whether a piece of hardware has the resources available to support abstraction in the form of virtualization or containers or not, whether it is on a LAN or a WAN relative to the users/processes it serves (compute for time-critical vs. sensitive workloads will always be deployed on a LAN), and whether compute hardware is deployed in a secure data center or is physically accessible.
The taxonomy also seeks to comprehend a balance of interests spanning the cloud, telco, service provider, IT, OT, IoT, mobile, and consumer spaces, providing each market with a foundation to build their specific language on top of. The chart below is a preview from the white paper and highlights the top edge tiers, subcategories and associated general trends.
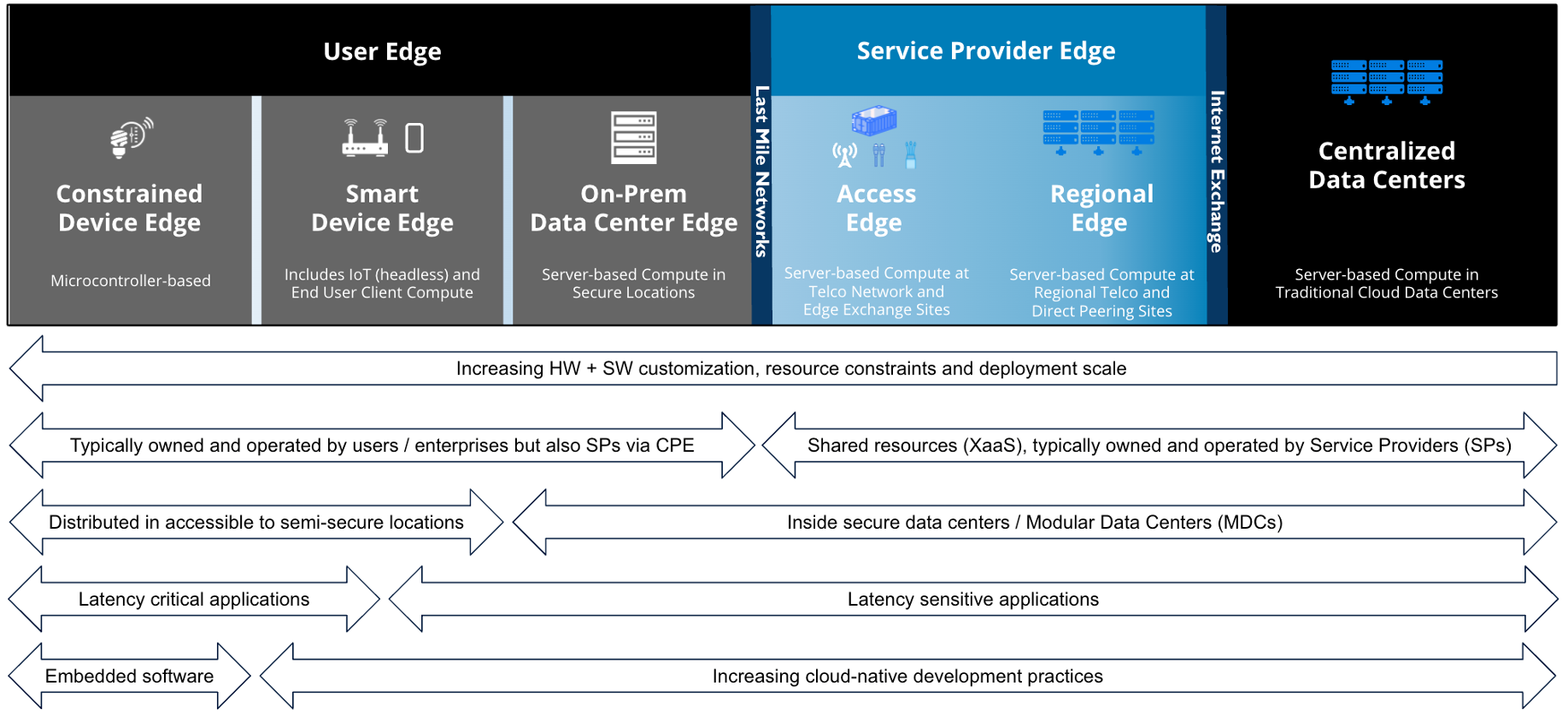
A key concept is that both hardware and software inherently get increasingly complex the closer you get to the physical world, and for this reason deploying AI at the edge introduces additional challenges. First and foremost is accommodating the heterogeneity of edge hardware spanning form factor and compute capability — devices that can be as simple as a constrained sensor conveying temperature changes to as complex as the brains of an autonomous vehicle which is basically a data center on wheels.
As a general rule, the closer deployments get to the physical world, the more resource-constrained they become. As such, deploying AI models at the User Edge compared to in secure, centralized data centers introduces a number of different complexities. While many of the same principles can be applied across the continuum, inherent technical tradeoffs dictate that tool sets can’t be exactly the same spanning server-class infrastructure at the Service Provider and On-prem Data Center Edges and the increasingly constrained and diverse hardware at the Smart and Constrained Device Edges as described in the LF Edge paper. Deploying edge compute and AI tools outside of physically-secure data centers also introduces new requirements such as a zero-trust security model and zero-touch deployment capability to accommodate non-IT skill sets.
Stakeholders from IT and OT administrators to developers and data scientists need robust remote orchestration tools to not only be able to initially deploy infrastructure and AI models at scale in the field, but also continue to monitor and assess the overall health of the system. Here at ZEDEDA, our focus is helping customers orchestrate compute hardware and applications at the IoT Edge which is a subcomponent of the Smart Device Edge in the LF Edge taxonomy. Traditional data center orchestration tools are not well-suited for these edges because they are too resource-intensive, don’t comprehend the scale factor or pre-suppose a near-constant network connection to the central console which often isn’t the case in remote IoT environments.
How do you decide where to deploy AI models along the edge continuum?
The decision on where to train and deploy AI models can be determined by balancing considerations across six vectors: scalability, latency, autonomy, bandwidth, security, and privacy.
In terms of scalability, in a perfect world we’d just run all AI workloads in the cloud where compute is centralized and readily scalable, however the benefits of centralization must be balanced out with the remaining factors that tend to drive decentralization. For example, we’ll depend on edge AI for latency-critical use cases and for which autonomy is a must, for example you would never make a decision to deploy a vehicle’s airbag from the cloud when milliseconds matter, regardless of how fast and reliable your broadband network may be under normal circumstances. As a general rule, latency-critical applications will leverage edge AI close to the process, running at the Smart and Constrained Device Edges as defined in the paper. Meanwhile latency-sensitive applications will often take advantage of higher tiers at the Service Provider Edge and in the cloud because of the scale factor.
In terms of bandwidth consumption, the deployment location of AI solutions spanning the User and Service Provider Edges will be based on a balance of the cost of bandwidth (e.g., land line vs. cellular vs. satellite come with increasing expense), the capabilities of devices involved and the benefits of centralization for scalability. Examples of use cases where the edge has… well… the edge… in terms of bandwidth savings include anything involving computer vision or vibration measurements — both of which involve continuous streams of high-bandwidth data. For these use cases, the analysis will often be done locally and only critical events will be triggered to backend systems. For example, messages along the lines of “the person at the door looks a little shifty” or “please send a tech, this machine is about to fail”.
When it comes to security, edge AI will be used in safety-critical applications where a breach has serious consequences and therefore cloud connectivity is either not allowed or only enabled via a data diode, for example monitoring for process drift in a nuclear power plant. Finally, AI will be increasingly deployed at the edge for privacy-sensitive applications in which Personally Identifiable Information (PII) must be stripped before a subset of data is backhauled to the cloud for further analysis.
Given all the benefits, will the edge eventually replace the cloud?
No, and there’s a lot of click-bait out there to this effect. It’s important to remember that the edge will not supplant the cloud, rather edge and cloud resources will work together as part of a broader continuum. We’ll continue to use the cloud for tasks that are resource-intensive and that require centralization, such as training AI models with large data sets, identifying patterns in large data sets with inference models such as in medical research, and for call center chat bots. Meanwhile, an example of an AI workload that relies on both the edge and cloud is natural language processing for smart speakers (i.e., Google Home, Amazon Echo). Part of the process is offloaded to these constrained devices but the cloud will continue to be leveraged for more complex voice analysis and returning search results.
In Closing
In this installment we talked through some key definitions and considerations when it comes to deploying edge AI. The ultimate consideration is architecting properly today to be able to deploy AI anywhere because we haven’t even scratched the surface on where we’ll see this powerful technology take us in the future.
Stay tuned for Part Two of this series dropping tomorrow in which we talk to some important edge AI use cases, additional considerations for scale, and where things are headed in terms of trends.