
Breaking Down the Edge Continuum
Written by Kurt Rinehart, Director of Data Science at Section. This blog originally ran on the Section website. For more content like this, please click here.
There are many definitions of “the edge” out there. Sometimes it can seem as if everyone has their own version.
LF Edge, an umbrella organization that brings together industry leaders to build “an open source framework for the edge,” has a number of edge projects under its remit, each of which seeks to unify the industry around coalescing principles and thereby accelerate open source edge computing developments. Part of its remit is to define what the edge is, an invaluable resource for the edge community to coalesce around.

Latest LF Edge White Paper: Sharpening the Edge
In 2018, State of the Edge (which recently became an official project of LF Edge) put out its inaugural report, defining the edge using four criteria:
- “The edge is a location not a thing;
- There are lots of edges, but the edge we care about today is the edge of the last mile network;
- This edge has two sides: an infrastructure edge and a device edge;
- Compute will exist on both sides, working in coordination with the centralized cloud.”
Since that inaugural report, much has evolved within the edge ecosystem. The latest white paper from LF Edge, Sharpening the Edge: Overview of the LF Edge Taxonomy and Framework, expands on these definitions and moves on from simply defining two sides (the infrastructure and the device edge) to use the concept of an edge continuum.
The Edge Continuum
The concept of the edge continuum describes the distribution of resources and software stacks between centralized data centers and deployed nodes in the field as “a path, on both the service provider and user sides of the last mile network.”
In almost the same breath, LF Edge also describes edge computing as essentially “distributed cloud computing, comprising multiple application components interconnected by a network.”
We typically think of “the edge” or “the edges” in terms of the physical devices or infrastructure where application elements run. However, the idea of a path between the centralized cloud (also referred to as “the cloud edge” or “Internet edge”) and the device edge instead allows for the conceptualization of multiple steps along the way.
The latest white paper concentrates on two main edge categories within the edge continuum: the Service Provider Edge and the User Edge (each of which is broken down into further subcategories).
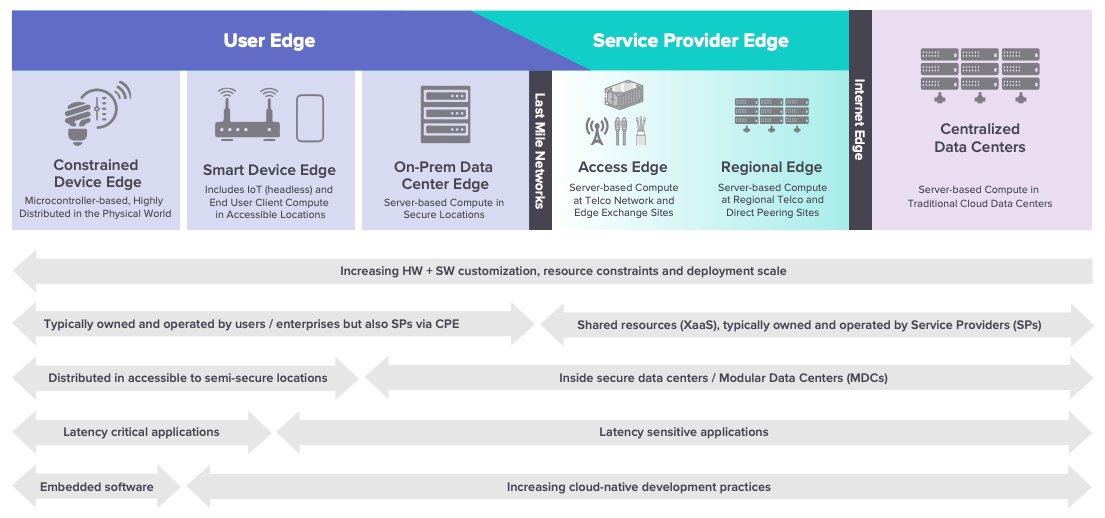
Image source: LF Edge
The Service Provider Edge and the User Edge
LF Edge positions devices at one extreme of the edge continuum and the cloud at the other.
Next along the line of the continuum after the cloud, also described as “the first main edge tier”, is the Service Provider (SP) Edge. Similarly to the public cloud, the infrastructure that runs at the SP Edge (compute, storage and networking) is usually consumed as a service. In addition to the public cloud, there are also cellular-based solutions at the SP Edge, which are typically more secure and private than the public cloud, as a result of the differences between the Internet and cellular systems. The SP Edge leverages substantial investments by Communications Service Providers (CSPs) into the network edge, including hundreds of thousands of servers at Points of Presence (PoPs). Infrastructure at this edge tier is largely more standardized than compute at the User Edge.
The second top-level edge tier is the User Edge, which is on the other side of the last mile network. It represents a wider mix of resources in comparison to the SP Edge, and “as a general rule, the closer the edge compute resources get to the physical world, the more constrained and specialized they become.” In comparison to the SP Edge and the cloud where resources are owned by these entities and shared across multiple users, resources at the User Edge tend to be customer-owned and operated.
Moving from the Cloud to the Edge
What do we mean when we talk about moving from the cloud to the edge? Each of the stages along the edge continuum take you progressively closer to the end user. You have high latency and more compute in the centralized cloud versus low latency and less compute as you get closer to the User Edge. When we talk about moving from the cloud to the edge, it means we want to leverage the whole stack and not solely focus on the centralized cloud.
Let’s look at the most obvious use case: content delivery networks (CDNs). In the 1990s, Akamai created content delivery networks to allow localized websites to serve a global audience. A website based in New York could leverage Akamai’s distributed network of proxy servers and data centers around the world to be able to store their static assets globally, including HTML, CSS, JavaScript, video, and images. By caching these in Akamai’s distributed global points of presence (PoP), the website’s end users worldwide were guaranteed high availability and consistent performance.
These days, CDNs are considered to be only one layer in a highly complex Internet ecosystem. Content owners such as media companies and e-commerce vendors continue to pay CDN operators to deliver their content to end users. In turn, a CDN pays ISPs, carriers, and network operators for hosting its servers in their data centers. That’s the Service Provider Edge we’re talking about.
An edge compute platform is still a geographically distributed network, but instead of simply providing proxy servers and data centers, an edge compute platform also offers compute. How do we define this? Compute can be defined as many things, but essentially, it boils down to the ability to run workloads wherever you need to run them. Compute still gives you high availability and performance, but it also allows for the capability to run packaged and custom workloads positioned relatively spatially to users.
An edge compute platform leverages all available compute between the cloud provider and the end user, together with DevOps practices, to deliver traditional CDN and custom workloads.
Applying Lessons from the Cloud to the Edge
We can take the lessons we’ve learned in the cloud and apply them to the edge. These include:
- Flexibility – At Section, we describe this as wanting to be able to run “any workload, anywhere”, including packaged and customized workloads;
- Taking a multi-provider approach to deployments – This offers the opportunity to create a higher layer of abstraction. Infrastructure as Code (IaC) is the process of managing and provisioning computer data centers through machine-readable definition files as opposed to physical hardware configuration or interactive configuration tools. At Section, we have 6-7 different providers, from cloud providers to boutique providers to bare metal providers.
- Applying DevOps practices – In order to provide the capabilities that the cloud has at the infrastructure edge, we need to enable developers to get insight and to run things at the edge at speed, just as they did in the cloud. This is DevOps. It’s important to be able to apply DevOps practices here since, “if you build it, you own it”. You want to make things open, customizable, and API-driven with integrations, so that developers can leverage and build on top of them.
- Leveraging containerized workloads – Deploying containers at the edge involves multiple challenges, particularly around connectivity, distribution and synchronization, but it can be done, and in doing, allows you to leverage this architecture to deploy your own logic, not just pre-packaged ones. Containerization also offers:
- Security
- Standardization
- Isolation; and
- A lightweight footprint.
- Insights and Visibility – We need to give developers deep, robust insight into what’s happening at the edge, just as we do in the cloud. The three pillars of observability are logs, metrics and tracing. An ELK stack can provide this, giving developers the invaluable ability to understand what is happening when things inevitably go wrong.
Edge Computing Use Cases in the Wild
There are many examples of use cases already operating at the Edge. A few of the many interesting ones out there include:
- Facebook Live – When you see a live stream in your feed and click on it, you are requesting the manifest. If the manifest isn’t already on your local PoP, the request travels to the data center to get the manifest, and then fetches the media files in 1 second clips. ML algorithms operate on the 1 second clips to optimize them in real time to deliver the best, fastest experience for users.
- Cloudflare Workers – These are Service Worker API implementations for the Cloudflare platform. They deploy a server-side approach to running JavaSCript workloads on Cloudflare’s global network.
- Chick-fil-A – A surprising one. Chick-fil-A has been pushing into the device edge over the last couple of years. Each of their 20,000 stores has a Kubernetes cluster that runs there. The goal: “low latency, Internet-independent applications that can reliably run our business”, in addition to high availability for these applications, a platform that enables rapid innovation, and the ability to horizontally scale.
We’re Not Throwing Away the Cloud
One last thing to make clear: we’re not talking about throwing away the cloud. The cloud is going nowhere. We will be working alongside it, using it. What we’re talking about is moving the boundary of our applications out of the cloud closer to the end user, into the compute that is available there. And, as we’ve seen, we don’t need to throw away the lessons we’ve learned in the cloud; we can still use the tools that we’re used to, plus gain all the advantages that the edge continuum has to offer.
You can download the LF Edge taxonomy white paper here. You can also watch the LF Edge Taxonomy Webinar, which shares insight from the white paper, on our Youtube Channel. Click here to watch it now.